 | Chapter 9 |  |

| Chapter 9 | |
Perl is the most commonly used language for CGI programming on the World Wide Web. The Common Gateway Interface (CGI) is an essential tool for creating and managing comprehensive web sites. With CGI, you can write scripts that create interactive, user-driven applications.
CGI allows the web server to communicate with other programs that are running on the same machine. For example, with CGI, the web server can invoke an external program, while passing user-specific data to the program (such as what host the user is connecting from, or input the user has supplied through an HTML form). The program then processes that data, and the server passes the program's response back to the web browser.
Rather than limiting the Web to documents written ahead of time, CGI enables web pages to be created on the fly, based upon the input of users. You can use CGI scripts to create a wide range of applications, from surveys to search tools, from Internet service gateways to quizzes and games. You can increment the number of users who access a document or let them sign an electronic guestbook. You can provide users with all types of information, collect their comments, and respond to them.
For Perl programmers, there are two approaches you can take to CGI. They are:
Programs that handle all CGI interaction directly, without the use of a module such as CGI.pm. While often frowned upon by Perl programmers because it's more likely to introduce bugs, bypassing the modules has the advantage of avoiding the overhead of CGI.pm for quick, dirty tasks. This chapter explains the concepts of CGI necessary if you intend to write CGI programs from scratch.
CGI.pm is a Perl module designed to facilitate CGI programming. For non-trivial CGI programs, especially ones that need to maintain state over multiple transactions, CGI.pm is indispensable, and is included in the standard Perl distribution as of Perl 5.004. Rather than discuss it in Chapter 8, Standard Modules, with the rest of the standard libraries, however, its complexity and importance made it a candidate for its own chapter, Chapter 10, The CGI.pm Module.
One performance hit for CGI programs is that the Perl interpreter needs to be started up each and every time a CGI script is called. For improving performance on Apache systems, the mod_perl Apache module embeds the Perl interpreter directly into the server, avoiding the startup overhead. Chapter 11, Web Server Programming with mod_perl, talks about installing and using mod_perl.
For an example of a CGI application, suppose you create a guestbook for your website. The guestbook page asks users to submit their first name and last name using a fill-in form composed of two input text fields. Figure 9.1 shows the form you might see in your browser window.
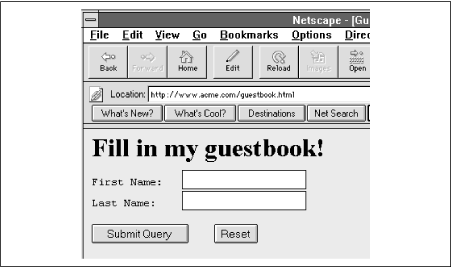
The HTML that produces this form might read as follows:
The form is written using special "form" tags, as follows:<HTML><HEAD><TITLE>Guestbook</TITLE></HEAD> <BODY> <H1>Fill in my guestbook!</H1> <FORM METHOD="GET" ACTION="/cgi-bin/guestbook.pl"> <PRE> First Name: <INPUT TYPE="TEXT" NAME="firstname"> Last Name: <INPUT TYPE="TEXT" NAME="lastname"> <INPUT TYPE="SUBMIT"> <INPUT TYPE="RESET"> </FORM>
The <form> tag defines the method used for the form
(either GET or POST) and the action to take when the
form is submitted - that is, the URL of the CGI program to
pass the parameters to.
The <input> tag can be used in many different ways. In its
first two invocations, it creates a text input field and defines
the variable name to associate with the field's contents when the
form is submitted. The first field is given the variable name
firstname and the second field is given the name lastname.
In its last two invocations, the <input> tag creates a "submit"
button and a "reset" button.
The </form> tag indicates the end of the form.
When the user presses the "submit" button, data entered
into the <input> text fields is passed to the CGI program specified
by the action attribute of the <form> tag (in this
case, the /cgi-bin/guestbook.pl program).
Parameters to a CGI program are transferred either in the URL
or in the body text of the request. The method used to pass
parameters is determined by the method attribute to the <form>
tag. The GET method says to transfer the data within the URL
itself; for
example, under the GET method, the browser might initiate the HTTP
transaction as follows:
GET /cgi-bin/guestbook.pl?firstname=Joe&lastname=Schmoe HTTP/1.0
The POST method says to use the body portion of the HTTP request to pass parameters. The same transaction with the POST method would read as follows:
In both of these examples, you should recognize thePOST /cgi-bin/guestbook.pl HTTP/1.0 ... [More headers here] firstname=Joe&lastname=Schmoe
firstname and
lastname variable names that were defined in the HTML form,
coupled with the values entered by the user. An ampersand (&) is
used to separate the variable=value pairs. The server now passes the variable=value pairs to the CGI program.
It does this either through Unix environment variables or in
standard input (STDIN).
If the CGI program is called with the GET method, then parameters
are expected to be embedded into the URL of the request, and
the server transfers them to the program by assigning them to the
QUERY_STRING environment variable. The CGI program can then
retrieve the parameters from QUERY_STRING as it would read any
environment variable (for example, from the %ENV hash in Perl).
If the CGI program is called
with the POST method, parameters are expected to be embedded
into the body of the request, and the server passes the body text
to the program as standard input (STDIN).
Other environment variables defined by the server for CGI store such information as the format and length of the input, the remote host, the user, and various client information. They also store the server name, the communication protocol, and the name of the software running the server. (We provide a list of the most common CGI environment variables later in this chapter.)
The CGI program needs to retrieve the information as appropriate and then process it. The sky's the limit on what the CGI program actually does with the information it retrieves. It might return an anagram of the user's name, or tell her how many times her name uses the letter "t," or it might just compile the name into a list that the programmer regularly sells to telemarketers. Only the programmer knows for sure.
Regardless of what the CGI program does with its input, it's responsible for giving the browser something to display when it's done. It must either create a new document to be served to the browser or point to an existing document. On Unix, programs send their output to standard output (STDOUT) as a data stream that consists of two parts. The first part is either a full or partial HTTP header that (at minimum) describes the format of the returned data (e.g., HTML, ASCII text, GIF, etc.). A blank line signifies the end of the header section. The second part is the body of the output, which contains the data conforming to the format type reflected in the header. For example:
In this case, the only header line generated is Content-type, which gives the media format of the output as HTML (Content-type: text/html <HTML> <HEAD><TITLE>Thanks!</TITLE></HEAD> <BODY><H1>Thanks for signing my guest book!</H1> ... </BODY></HTML>
text/html).
This line is essential for every CGI program, since
it tells the browser what kind of format to expect.
The blank line separates the header from the body text (which,
in this case, is in HTML format as advertised). The server transfers the results of the CGI program back to the browser. The body text is not modified or interpreted by the server in any way, but the server generally supplies additional headers with information such as the date, the name and version of the server, etc.
CGI programs can also supply a complete HTTP header itself, in which case the server does not add any additional headers but instead transfers the response verbatim as returned by the CGI program. The server needs to be configured to allow this behavior; see your server documentation on NPH (no-parsed headers) scripts for more information.
Here is the sample output of a program generating an HTML virtual document, with a complete HTTP header:
The header contains the communication protocol, the date and time of the response, and the server name and version. (HTTP/1.0 200 OK Date: Thursday, 28-June-96 11:12:21 GMT Server: NCSA/1.4.2 Content-type: text/html Content-length: 2041 <HTML> <HEAD><TITLE>Thanks!</TITLE></HEAD> <BODY> <H1>Thanks for signing my guestbook!</H1> ... </BODY> </HTML>
200 OK is a status code generated by the HTTP
protocol to communicate the status of a request, in this case
successful.)
Most importantly, the header also contains the content type and
the number of characters (equivalent to the number of bytes)
of the enclosed data.The result is that after users click the "submit" button, they see the message contained in the HTML section of the response thanking them for signing the guestbook.
|  | |
| IV. CGI |  | 9.2 URL Encoding |